DATA STREAMING IN MULESOFT 4
DATA STREAMING IN MULE 4
- Bharath Venkata
This blog post mainly focus on sorting out the Huge Data transfer issues in mule 4 with the concept of Streaming .
Main problem with huge data load transfer is Java Heap out of memory and the CPU performance , To address this problem MuleSoft has a beautiful concept named STREAMING ✊
Activity :- Lift and Shift 2 M+ Records from CSV file into Postgres DB using Streaming concept.
Step 1 : To load the 2M+ records to database we need a huge sample data were we can find it here in the below mentioned link
Download Sample CSV Files for free - Datablist
Step 2 : We need to load this sample CSV file which holds 2 M records to Database using mulesoft Streaming concept
Mule flow for transferring 2M + CSV data to Database

File Read Config : Enable Streaming in MIME TYPE section as Shown below


Dataweave Streaming : DataWeave supports end-to-end streaming through a flow in a Mule application. Streaming speeds the processing of large documents without overloading memory.


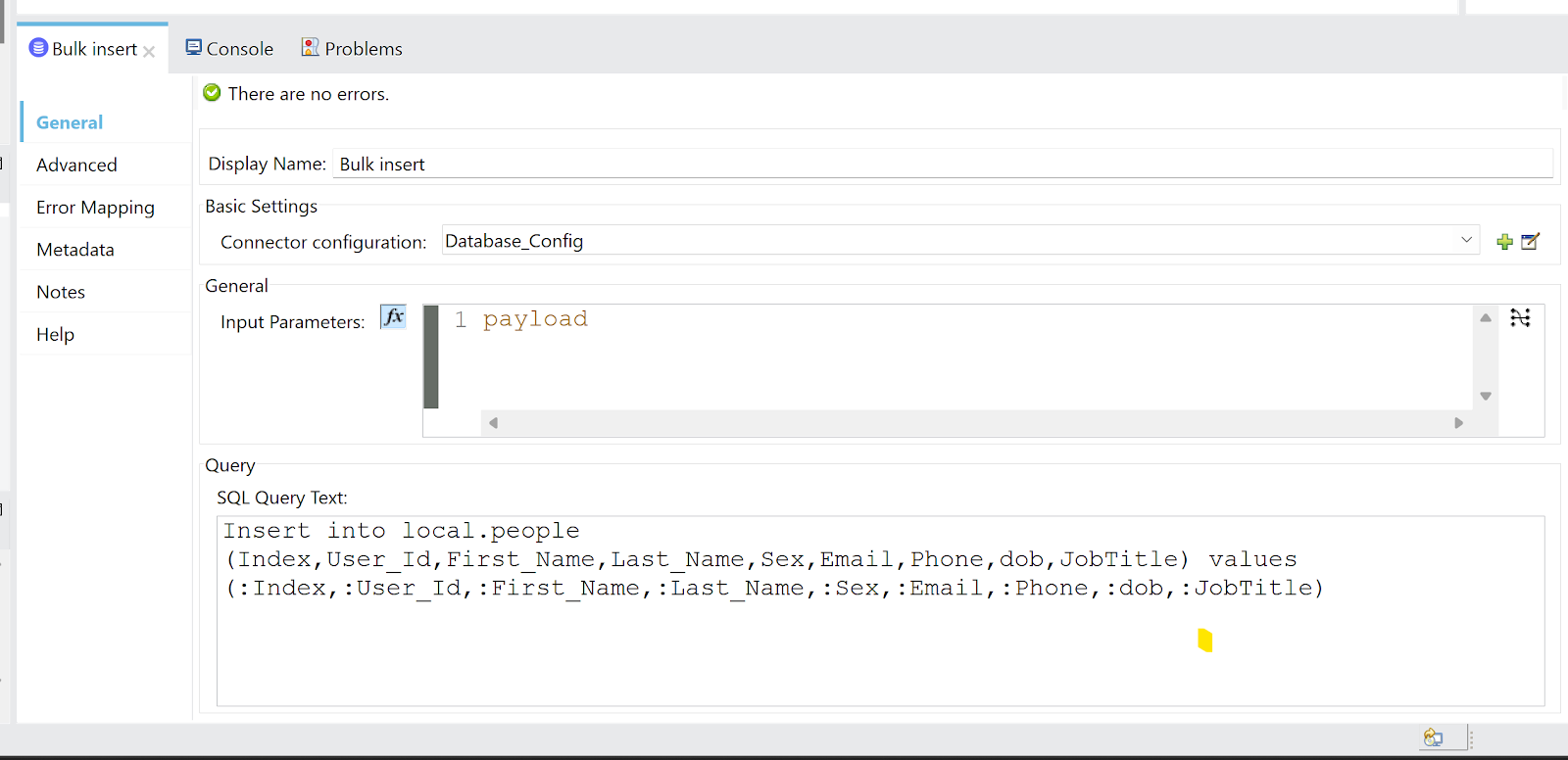
Here is the bulk insert query


Good blog venkat. Can you advise how much vcore consumed by the app for this task? Thanks
ReplyDelete0.1 * 2 is enough with 1 worker each .... It won't cost any cpu as it is synchronised process... It will be like after one chunk of data consumption is done.. it will go for another fetch..and so on..
ReplyDeletein this POC, which database connection was used?
ReplyDeleteIt's postgre db
Deletenice ..................!
ReplyDeletemulesoft training
pega training
servicenow training training